
Spring Boot
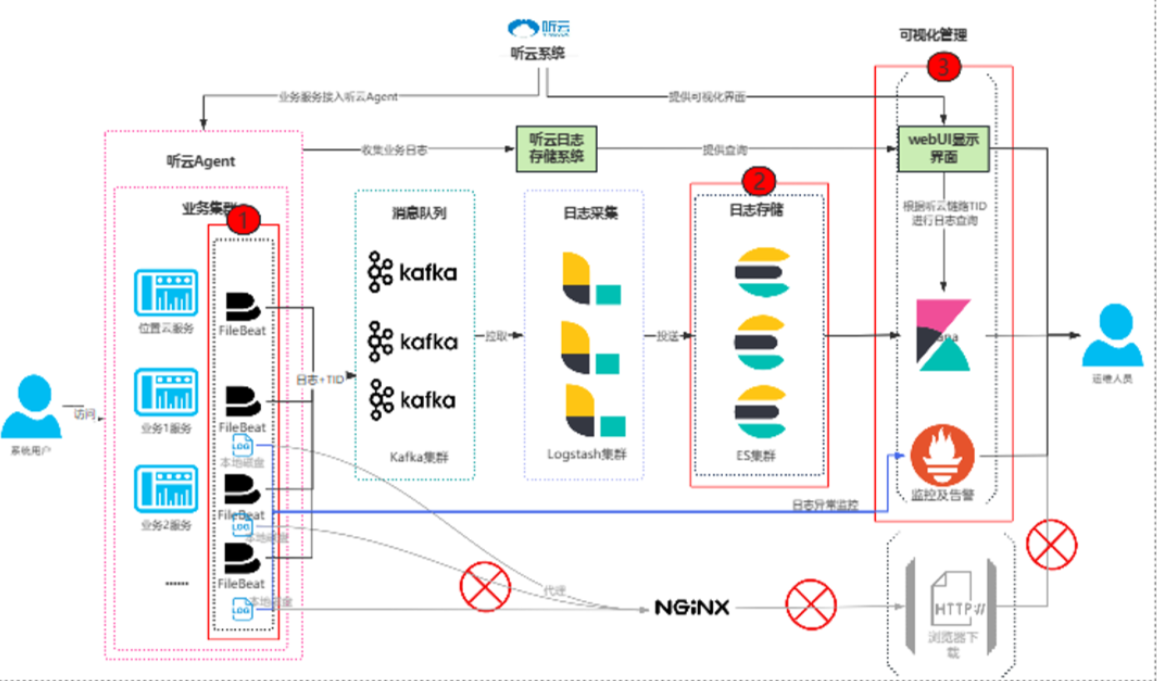
未读日志系统完善方案背景现状当前业务环境没有统一的日志输出格式,日志文件只能通过HTTP下载,运维人员处理效率低,需要将服务接入日志系统规范及适配性改造等(约150个微服务);服务增加日志采集(约100个微服务) 目标通过完善日志系统集中收集日志,升级日志链路ID规范,通过打通日志系统链路ID和听云系统链路ID;提高运维效率,缩短问题定位时间由原来的2天降低至1天内 技术栈选择 采集层:Filebeat(轻量级日志采集) 缓冲层:Kafka(高吞吐消息队列,削峰填谷) 处理层:Logstash(日志解析、过滤、富化) 存储层:Elasticsearch(分布式搜索与存储) 展示层:Kibana(可视化分析与仪表盘) 现状与升级后对比总览 系统设计 应用程序日志采集设计 业务集群变更: 在启动命令中加入听云Agent,日志输出时调用链路ID。 统一日志输出模板,升级服务接入日志规范。 日志系统收集全部业务日志。 修改本地存储日期策略,节省服务器磁盘空间。 提供日志收集级别配置,根据实际情况调整日志收集级别。 日志滚动生成:定义并规范日志输出的统一格式,确保日志按一定规则滚动生成。 Fi ...
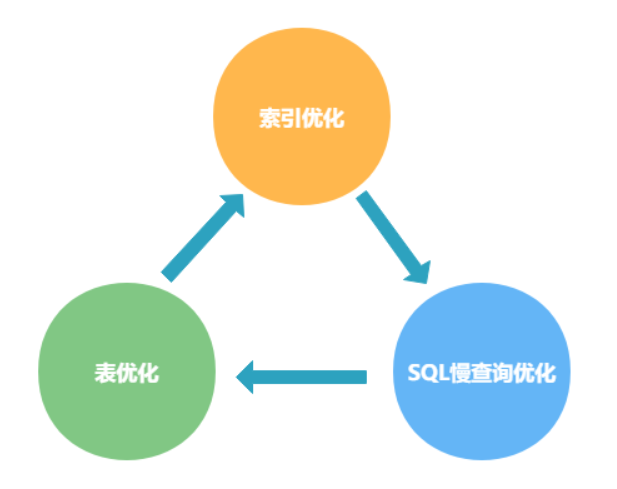
车辆综合查询报表接口优化背景: 通过日志平台对车辆综合查询接口的响应时间进行分析,发现当前接口的平均响应时间比较长,为了提高用户使用的体验,需要对接口进行优化 目的: 整理用户权限和组织权限之间的区别和涉及到的表信息 基础节点信息的表改造,添加排序字段,优化查询速度 相关接口: /car/queryMonitorList /optimize/queryFuelCarList 对接口调用链路分析: 分析发现,主要还是SQL层面的响应时间比较长,所以从SQL进行优化 流程: 首先调用车辆综合报表方法xxQueryFuelCarList 进入查询车辆车次计数xxCarAllCount 遍历车辆节点表xx_Node_CarInFo_Car找到对应节点 对应节点车辆的基础信息表xx_Node_relationship 基础节点SQL 123456789101112131415-- 执行查询,查找根节点及其所有后代节点SELECT id, nameFROM ( SELECT t1.id, t1.pid, ...

MySQL
未读大体量业务数据表迁移方案全量+增量混合迁移 背景分析对大体量业务数据表和归档数据表字段进行查询后,整理出所有非create_time的表如下所示: 大体量业务数据表中非create_time的表: hy_business_platform_log (LOG_DATE) ota_eol_message_log (req_time) 归档数据表中非create_time的表: driving_behavior_xx(create_date) archive_driving_behavior_xx(create_date) 由于大部分表都有create_time字段,因此全量和增量迁移都基于create_time进行数据分片,具体执行方案如下。 全量迁移:1、数据导入:将临时存储区的全量数据迁移至新建的归档数据库。 创建迁移配置表 1234567891011CREATE TABLE migration_config ( id BIGINT AUTO_INCREMENT PRIMARY KEY, source_db_name VARCHAR(128) NOT NULL C ...

Java并发
未读ReentrantLock 深度剖析 ReentrantLock 是 JUC 包中最重要的锁实现,理解其原理对于掌握 Java 并发编程至关重要。 一、ReentrantLock 概述ReentrantLock 是基于 AQS(AbstractQueuedSynchronizer)实现的可重入独占锁,相比 synchronized 提供了更丰富的功能特性。 1.1 核心特性 特性 说明 可重入 同一线程可多次获取锁,通过 state 计数器实现 公平/非公平 可选择按 FIFO 顺序获取锁或允许插队 可中断 支持 lockInterruptibly() 响应中断 超时获取 支持 tryLock(timeout) 限时等待 多条件变量 支持多个 Condition 队列 1.2 内部结构123456789101112131415public class ReentrantLock implements Lock, java.io.Serializable { private final Sync sync; // 同步器 ...

LM Studio 介绍:LM Studio是一款能够本地离线运行各类型大语言模型的客户端应用,通过LM Studio 可以快速搜索所需的llms类型的开源大语言模型,并进行运行。 通过使用LM Studio 在本地运行大语言模型可以更加快速的运行流畅的提问,并在独立的环境中保障数据不被监听和收集。 特点:本地、独立、离线 官网:https://lmstudio.ai/ 参考文档:docs 步骤:首先进入官网Download下载页面,选择自己电脑的操作系统点击下载安装包 下载完成之后根据步骤安装好后双击进入 点击右上角的Skip onboarding跳过 接着点击UI界面中间的“Select a model to load”,开始搜索模型,第一次搜索会显示No result found,列表可以看到,但无法进行下载模型。这个时候不要慌,因为https://huggingface.co/ 在国内是无法访问的 在软件内部获取模型的是通过https方式来访问的,全局代理也没有过去,因此科学上网也用不了 这时候只能用国内的同步的镜像: hf-mirror.com,用于替换镜像 huggi ...
项目实战
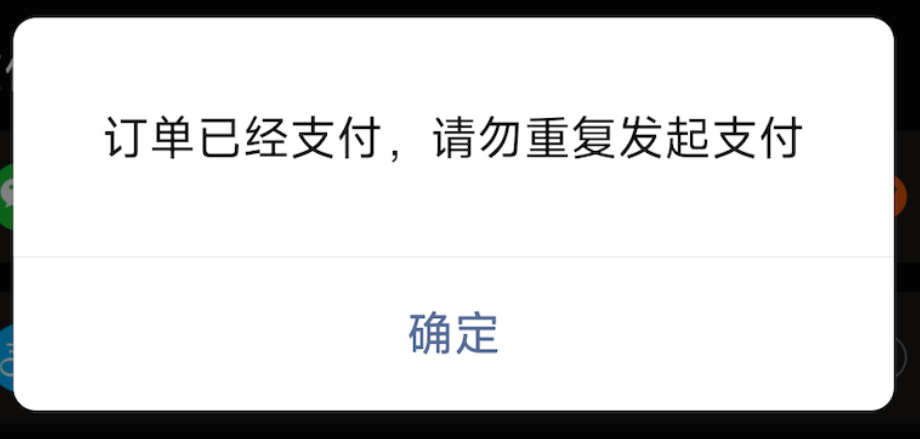
未读如何避免用户重复下单(多次下单未支付,占用库存)场景回顾 在稀有商品抢购或秒杀场景中,一个用户多次下单未支付可能是恶意锁库存或损坏其他用户的权益,因此需要避免用户重复下单。 1)首先前端需要进行按钮控制 在用户点击“下单”按钮后,可以通过前端控制按钮状态,比如变为“处理中”或“请稍等”,避免用户在等待过程中多次点击按钮,导致重复下单请求发送到后端。但是前端的操作无法完全避免重复请求,因此需要与后端的幂等控制结合,以确保不会因多次点击创建多个订单。 2)在每次下单请求中生成一个唯一的requestId或token 用户进入订单页面前,前端会先请求后端生成这次请求的唯一的requestId或token,然后在每次下单请求中带上这个唯一的requestId或orderToken。这样后端可以通过检测该标识是否已存在,来决定是否创建新订单。这样,无论用户重复点击几次下单按钮,仅会创建一次订单。 以上两步能阻挡绝大部分用户正常操作下的重复下单行为,如果一些用户通过 api 请求,或者后退页面再次点击下单进入,还是可以重复下单,不过一般这种设计已经可以杜绝稀有商品抢购或秒杀场景的恶意锁库存了, ...

运维部署
未读白嫖华为云400元代金卷各位码友们,白嫖ESC服务器的活动来啦,可以免费领取1年的华为云服务器,给你的项目上线或者搭建私人博客~ 具体奖励: 两个都选代金卷的话还是很香的 给大家看看之前白嫖代金卷领的服务器: 之前活动领取的包,皮质,质量还是不错的 前置条件首先点击报名链接报名:https://edu.huaweicloud.com/signup/c586933f7a12484aa2afb4696d2629e8?medium=share_kfzlb&invitation=d2139abb8e254557b3dd2af10685bdd9 具体步骤一:完成任意云实验 打开报名链接,找到云实验的实验列表: 完成五个实验其中一个就可以抽奖,这里我选的是最后一个: 点击开始实验之后,根据窗口左侧的实验手册按步骤来就能过,大概用时10分钟,相信聪明的码友们都没问题o.o 实验完成后点击链接抽奖:https://survey.huaweicloud.com/survey/#/qtn?id=7af9f98b8b904c2fb8603742bd112b5d 这里选择自己做的实验 ...

MySQL
未读MySQL 连接池是什么?存储连接的池子,本质上是一种资源复用技术。 作用:节约连接创建的成本,提升流程处理的效率。 注意:连接池是在 MySQL 的客户端一侧。 连接池的价值短连接在高并发场景下反复建立连接成本很高,使用长连接用完后不关闭。 价值:实现连接资源的复用 连接池常见参数参数控制 MySQL 的连接复用策略,一般由客户端引擎(Java 库)实现。 通常客户端支持的主要参数: 最大空闲连接数/连接池个数(长连接个数): 连接池中最多有多少个空闲连接, 理解为:一共可以维护多少个长连接来节约连接建立的成本。 空闲时间(长连接的持续性):表面了连接池中的连接在空闲时在池子里面可以摸鱼多久,便于节约资源。1-10s 左右 最小连接数:连接池中最小的空闲连接,当连接数小于这个值时,连接池会自动创建新的连接来进行补充。 作用:保持连接池处于就绪状态。 使用场景:需要的长连接比较多,且请求是周期性的。eg.晚上跑脚本触发请求。 初始化连接数:意义不大,由最小连接数补齐。 Druid 的连接池参数(Java) maxActive:连接池中的最大连接个数,也就是我 ...

Redis
未读1.Redis中常见的数据类型有哪些? String:可以存储任何类型的数据,最大长度为512MB 使用场景:缓存 Session、Token、图片地址、序列化后的对象、页面单位时间的访问数、分布式锁等 Set:存储无序且不重复的字符串集合,使用哈希表实现可以基于 Set 轻易实现交集、并集、差集的操作,支持快速查找和去重操作 使用场景:文章点赞、共同好友(交集)、共同粉丝(交集)等 zSet:存储有序的字符串集合,类似于set但是增加了权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表 使用场景:各种排行榜、优先级任务队列等 Hash:存储键值对,适合用于存储对象 使用场景:用户信息、商品信息、文章信息、购物车信息等 List:集合,使用双向链表实现,可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 使用场景:最新文章、最新动态、消息队列等 2.Redis为什么这么快主要有以下几个方面原因: 基于内存存储:Redis大部分数据都存储在内存中,相较于传统的基于磁盘的数 ...

项目实战
未读前言:我们有个上线到个人服务器的项目,如果想测试QPS,该怎么做?做法->选择一个合适的压力测试工具: Apache JMeter:功能强大,支持多种协议(推荐) wrk:轻量级工具,适合 HTTP 性能测试 ab(ApacheBench):简单易用,适合基础 HTTP 测试 k6:现代化工具,支持编程测试脚本 Locust:基于 Python,适合复杂测试场景 这里我们选择wrk进行压力测试,wrk是一个轻量级的工具,比较适合我们这种小型单体项目的测试 准备步骤: 首先准备一台Linux/Mac 在服务器上安装wrk,这里以阿里云部署的centos7.9为例 一.wrk安装在 CentOS 上安装 wrk 可以通过以下步骤完成: 1. 安装依赖运行以下命令,确保系统已安装必要的工具和库: 123sudo yum groupinstall "Development Tools" -ysudo yum install epel-release -ysudo yum install git gcc make openssl-devel -y ...
