

MySQL
未读1.InnoDB聚簇索引和非聚簇索引的区别InnoDB的底层是用B+树实现的,所以聚簇索引和非聚簇索引在默认情况下也是使用B+树实现,但是存在一定的差别,如下表所示: 区别 聚簇索引 非聚簇索引 叶子节点存储内容 完整数据 主键、索引列 在表中是否唯一 是 否 适用场景 范围查询、排序操作 快速查找数据 因为B+树的叶子节点之间是通过双向链表连接的,所以对于存储了数据行的聚簇索引来说在特定范围内进行数据查询和对数据进行排序操作不用修改数据的结构,IO次数减少查询速度快。而对于非聚簇索引,因为存储的是主键和索引列,想要通过非聚簇索引来查找完整的数据内容会增加回表的次数,造成IO次数的开销,因此查找完整的数据比较慢,但是用于快速查找特定数据,根据主键和索引列匹配数据会比聚簇索引快。 2.存储引擎有哪些?它们之间有什么区别?常见的存储引擎有MyISAM、InnoDB、Memory 在MySQL 5.5版本之前,默认的存储引擎是MyISAM 在MySQL 5.5版本之后,默认的存储引擎变为了InnoDB 而Memory是MySQL 3.23版本中引入的使用内存缓存数据, ...

问题回顾:在给项目引入了阿里的百炼大模型sdk后,然后运行Springboot,出现如下的报错信息,根据提示可以知道是有两个slf4j包,发生了冲突 参考的解决方案:[已解决] SLF4J: Class path contains multiple SLF4J bindings 开始解决该问题:既然是冲突,那可能就是项目中依赖了多个不同版本的slf4j类库,那如何分析到底是哪几个类库依赖了slf4j呢?我们可以使用dependency:tree命令: 1mvn dependency:tree 定位到发生冲突的包 方法1:知道了具体的依赖和子包我们就可以找到dashcope中引入的API依赖出现冲突,将其去掉即可了。 方法2:简单粗暴,直接删掉冲突的文件 1rm -f /app/aimian-backend-0.0.1-SNAPSHOT.jar/BOOT-INF/lib/slf4j-simple-1.7.36.jar

问题描述:当我们的项目上线后,使用IP地址可以正常对网页进行访问和登录,所有功能正常。 那么问题来了,给网站备案好之后,网站主页能够正常访问,但是登录时,发现返回的session被释放掉了 并且ip访问时cookie里有维持session,而域名访问时却没有,在尝试试了很多种方法,包括在后端设置cookieSerializer,都无法解决 解决思路:经过查阅资料之后,终于发现了问题所在: 前端现在是域名+端口 但是调用后端是ip+端口 违背同源策略了 跨域问题的原因 跨域问题是由浏览器的 同源策略(Same-Origin Policy) 引起的。同源策略要求: 协议、域名、端口都必须一致。 如果前端和后端运行在不同的域名、IP 或端口上,例如: 前端地址为 http://126.4.3.3 后端地址为 http://126.4.3.3:8080 浏览器会认为它们是不同源,因此会阻止请求,这是跨域问题的本质。 解决方法:在我们前端的转发路径中将原本的IP改为我们的子域名 通过 Nginx 的反向代理机制,将前端通过 /api 路径发起的请求转发到后端(即 http: ...

MySQL
未读MySQL 中的日志类型MySQL 提供多种日志类型,用于记录数据库运行中的各种信息,下面是常见的日志类型: 日志类型 功能 常见日志名称 适用场景 错误日志 记录服务器启动、关闭、运行中的错误和警告信息。 error.log 诊断服务器问题,例如启动失败、崩溃等。 查询日志 记录所有客户端请求(连接、查询、断开连接等)。 general_log 调试 SQL 查询语句,分析客户端行为。 慢查询日志 记录执行时间超过阈值的 SQL 语句。 slow.log 定位慢查询,优化查询性能和索引。 事务日志 记录事务执行相关信息,保证事务的 ACID 特性。 redo log / undo log 保证事务回滚、数据恢复、并发控制。 二进制日志 记录所有更改数据的操作,支持数据恢复和主从复制。 binlog 数据恢复、主从复制同步。 中继日志 从库存储主库的二进制日志,用于主从复制。 relay-log 从库重放主库的更改操作。 审计日志 记录用户的访问行为和操作,用于安全审计和合规性需求。 audit.log 数据安全监控与合规需求。 性能日 ...

MySQL
未读InnoDB中聚簇索引和非聚簇索引的区别InnoDB的底层是用B+树实现的,所以聚簇索引和非聚簇索引在默认情况下也是使用B+树实现,但是存在一定的差别,如下表所示: 区别 聚簇索引 非聚簇索引 叶子节点存储内容 完整数据 主键、索引列 在表中是否唯一 是 否 适用场景 范围查询、排序操作 快速查找数据 因为B+树的叶子节点之间是通过双向链表连接的,所以对于存储了数据行的聚簇索引来说在特定范围内进行数据查询和对数据进行排序操作不用修改数据的结构,IO次数减少查询速度快。 而对于非聚簇索引,因为存储的是主键和索引列,想要通过非聚簇索引来查找完整的数据内容会增加回表的次数,造成IO次数的开销,因此查找完整的数据比较慢,但是用于快速查找特定数据,根据主键和索引列匹配数据会比聚簇索引快。 扩展:Innodb数据存储结构从Mysql5.5版本开始,InnoDB是默认的表存储引擎。其特点是行锁设计、支持MVCC、支持外键、提供一致性非锁定读、同时被设计用来最有效的利用以及使用内存和CPU。 innodb的存储格式从行,页,区,段,再到表空间,环环相扣。接下来就介绍存储格式 i ...

一直在使用的markdown编辑器:Typora 其内部图片默认是存储在本机C盘中的,在使用blog编辑文档时想节省服务器的存储空间,于是采用cos将图片放到云端存储。 方法将typora中的图片上传到腾讯云的COS中 注意:在较新版本的Typora中(在MacOS上为0.9.9.32或在Windows / Linux上为0.9.84),添加了“上传图像”功能,可通过第3个应用程序或脚本将图像上传到云图像存储。 1.在COS中创建bucket 2.配置PicGo1、下载链接 链接 安装后上传设置: Secretld和SecretKey参考腾讯云cos配置文档 设置Server: 要想实现一键上传,必须要Typora和PicGo在同一端口上 同时记得把内置剪切板功能打开,否则上传图片会一直uploading! 3.打开Typora偏好设置 点击验证图片按钮: 验证成功即可

MySQL
未读MySQL 索引类型详解 索引是数据库优化的核心手段,理解不同索引类型的特点和适用场景,是写出高性能 SQL 的关键。 一、索引分类总览 分类维度 索引类型 数据结构 B+Tree、Hash、Full-Text、R-Tree 存储方式 聚簇索引、非聚簇索引 物理层级 主键索引、二级索引(辅助索引) 索引性质 主键索引、唯一索引、普通索引、前缀索引 字段个数 单列索引、联合索引(复合索引) 二、按数据结构分类2.1 B+Tree 索引(默认)MySQL 中最常用的索引类型,InnoDB 和 MyISAM 都基于 B+Tree 实现。 B+Tree 特点: 非叶子节点只存储 key 和指针,不存储数据 叶子节点存储所有 key 和数据,并通过双向链表连接 支持范围查询和排序 12-- 创建 B+Tree 索引(默认)CREATE INDEX idx_name ON users(name); 2.2 Hash 索引基于哈希表实现,等值查询 O(1) 复杂度。 优点 缺点 等值查询极快 不支持范围查询 结构简单 不支持排序 存在哈希冲 ...
MySQL
未读MySQL 存储引擎详解 存储引擎是 MySQL 的核心组件,不同引擎决定了数据的存储方式、索引结构、锁机制等关键特性。 一、什么是存储引擎?MySQL 采用插件式存储引擎架构,将查询处理与数据存储分离。存储引擎负责数据的存储和提取,不同引擎有不同的特性。 版本演进: MySQL 5.5 之前:默认 MyISAM MySQL 5.5 之后:默认 InnoDB(推荐使用) 二、主流存储引擎对比 特性 InnoDB MyISAM Memory 事务支持 ✅ ACID 事务 ❌ ❌ 锁粒度 行级锁 表级锁 表级锁 外键 ✅ 支持 ❌ ❌ MVCC ✅ 支持 ❌ ❌ 索引类型 B+Tree、全文索引 B+Tree、全文索引 Hash、B+Tree 崩溃恢复 ✅ redo log 恢复 ❌ ❌(数据丢失) 存储限制 64TB 256TB 取决于内存 适用场景 OLTP、高并发 只读/读多写少 临时表、缓存 2.1 InnoDB 核心特性为什么 InnoDB 是默认引擎? 事务安全:支持 ACID,提供 Commit、Rollback、崩 ...
Java并发
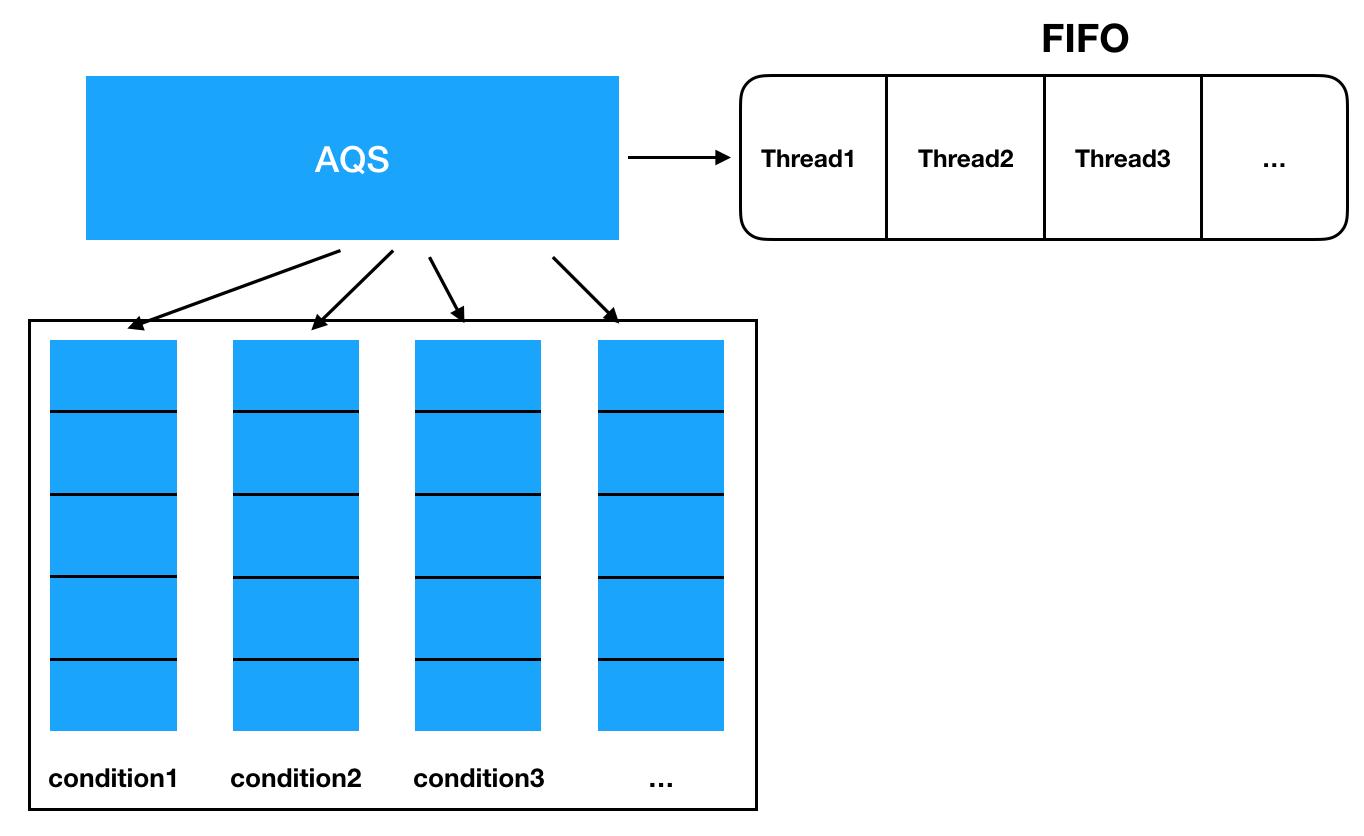
未读AQS 核心原理深度剖析 AQS 是 JUC 包的基石,理解 AQS 就理解了 Java 并发工具类的一半。 一、什么是 AQS?AQS(AbstractQueuedSynchronizer,抽象队列同步器)是 Doug Lea 设计的一个用于构建锁和同步器的框架。它抽象了锁的核心要素:状态管理 + 线程排队 + 阻塞唤醒。 1.1 基于 AQS 的实现类 同步器 使用模式 说明 ReentrantLock 独占 可重入互斥锁 ReentrantReadWriteLock 独占 + 共享 读写分离锁 Semaphore 共享 信号量,控制并发数 CountDownLatch 共享 倒计数门闩 CyclicBarrier 独占 循环屏障 1.2 核心设计思想AQS 采用模板方法模式,将通用逻辑(入队、出队、阻塞、唤醒)封装在父类,将同步状态的获取与释放逻辑留给子类实现。 123456// 子类需要实现的方法protected boolean tryAcquire(int arg) // 独占获取protected boolean tryRelea ...

Java并发
未读线程池深度解析 线程池是高并发系统的核心组件。理解其原理和参数调优至关重要。 一、为什么需要线程池?1.1 线程的开销创建一个线程的代价是昂贵的: 开销类型 说明 内存分配 每个线程需要分配约 1MB 栈内存 系统调用 创建/销毁涉及用户态到内核态切换 上下文切换 线程过多导致频繁切换,约 1-10 微秒/次 GC 压力 线程对象创建销毁增加 GC 负担 1.2 线程池的优势 降低资源消耗:复用线程,避免频繁创建销毁 提高响应速度:任务到达时无需等待线程创建 提高可管理性:统一分配、调优和监控 提供更多功能:定时执行、周期执行、并发数控制 二、ThreadPoolExecutor 核心参数123456789public ThreadPoolExecutor( int corePoolSize, // 核心线程数 int maximumPoolSize, // 最大线程数 long keepAliveTime, // 空闲存活时 ...
